
For the passion of revealing stories in relational data
We study information flows through social and biological systems to comprehend their inner workings. By simplifying myriad network interactions into maps of significant information flows, we can address research questions about how diseases spread, plants respond to stress, and life distributes on Earth. Our goal is to generate reliable predictions and suggest successful strategies to secure a sustainable future.

My work and interests

Maps of networks
Want to transform raw relational data into insightful maps and discoveries? Simplify and highlight important structures in networks with our tools available on mapequation.org

Helping businesses love their data
I am co-founder of Infobaleen together with Daniel Edler, Andrea Lancichinetti, Niklas Lovén, Christian Persson, and Jakob Sjölander. Infobaleen…

My journey in life and science
My life is an improv dance with family, cross-country skiing, outdoor fun, and research. I was born in Uppsala…

Welcome to IceLab!
I am a professor of physics with focus on computational science. You find me in Integrated Science Lab, IceLab, on…
Selected publications
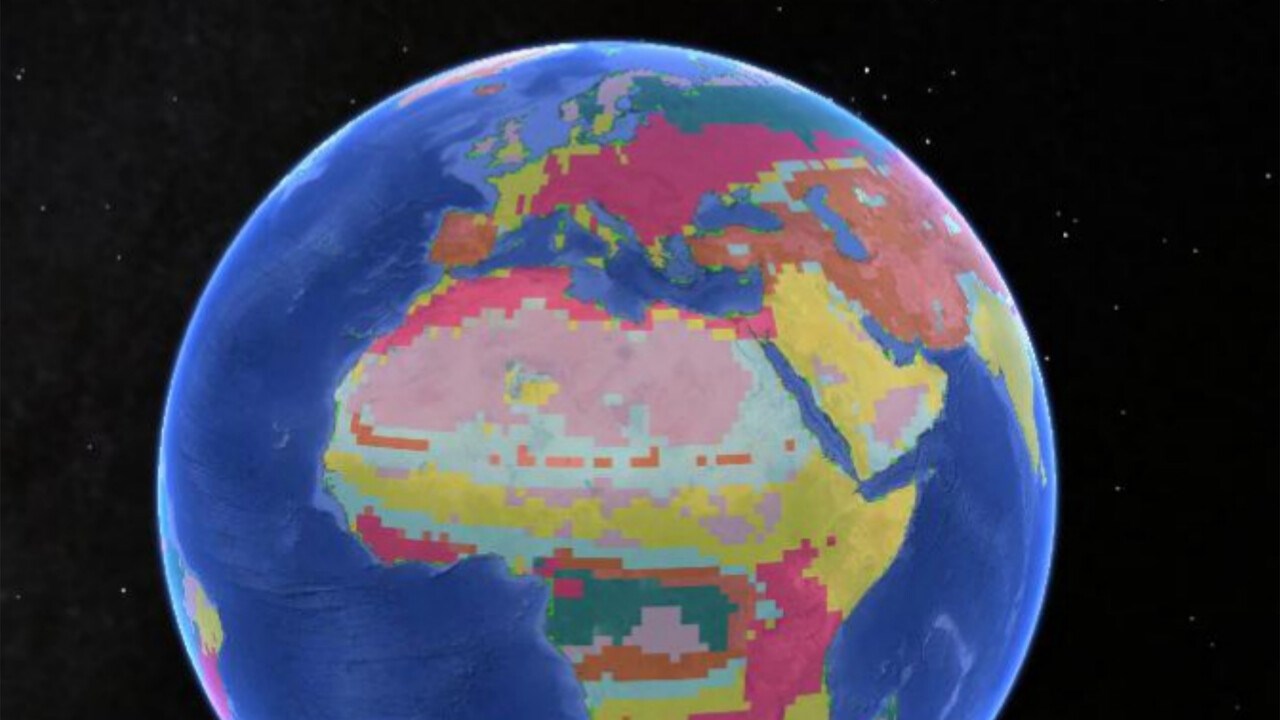
Regularities in species niches reveal the world’s climatic regions
The hypothesis of the Great Evolutionary Faunas is a foundational concept of macroevolutionary research postulating that three global mega-assemblages have dominated Phanerozoic oceans...
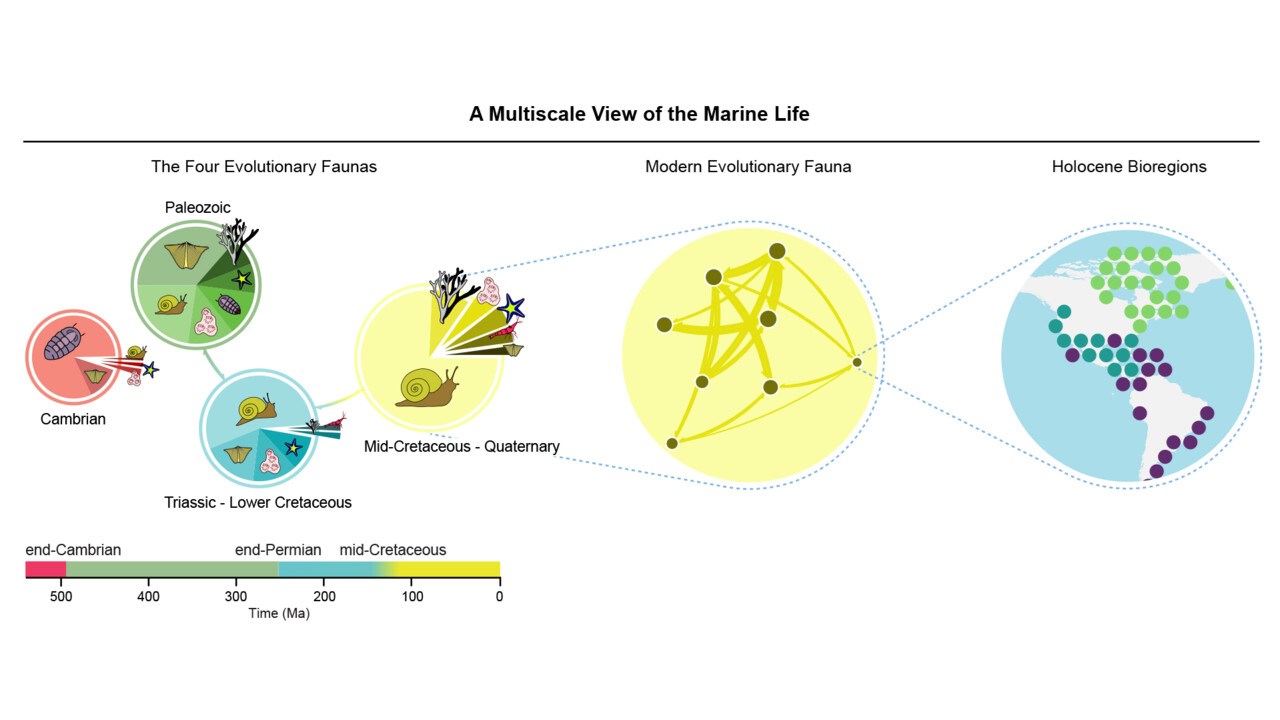
A multiscale view of the Phanerozoic fossil record reveals the three major biotic transitions
The hypothesis of the Great Evolutionary Faunas is a foundational concept of macroevolutionary research postulating that three global mega-assemblages have dominated Phanerozoic oceans...
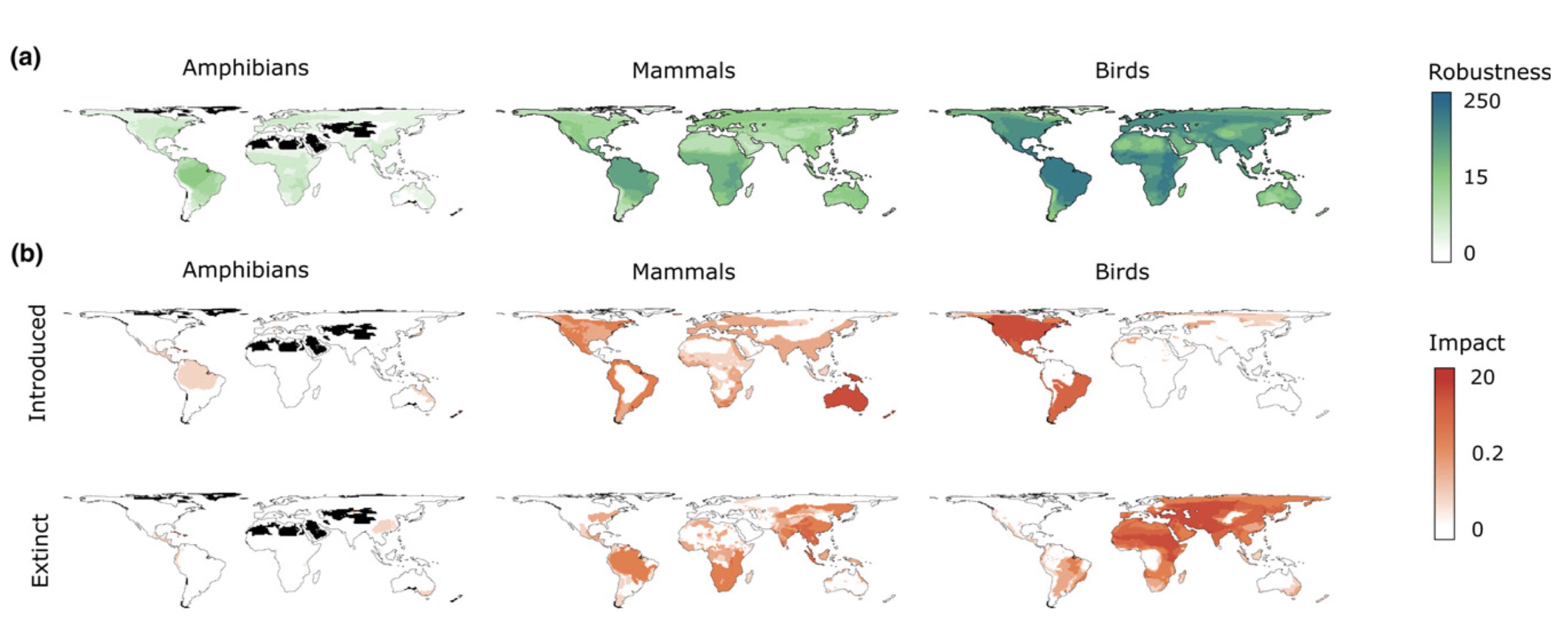
Human activity is altering the world’s zoogeographical regions
Zoogeographical regions, or zooregions, are areas of the Earth defined by species pools that reflect ecological, historical and evolutionary processes acting over millions of years...

Understanding Complex Systems: From Networks to Optimal Higher-Order Models
Rich data are revealing that complex dependencies between the nodes of a network may not be captured by models based on pairwise interactions. Higher-order network models go beyond these limitations, offering new perspectives for understanding complex systems.

Mapping change in large networks
Change is a fundamental ingredient of interaction patterns in biology, technology, the economy, and science itself: Interactions within and between organisms change; transportation patterns by air, land, and sea all change; the global financial flow changes; and the frontiers of scientific research change…

Maps of random walks on complex networks reveal community structure
To comprehend the multipartite organization of large-scale biological and social systems, we introduce a new information-theoretic approach to reveal community structure in weighted and directed networks…